

Článek
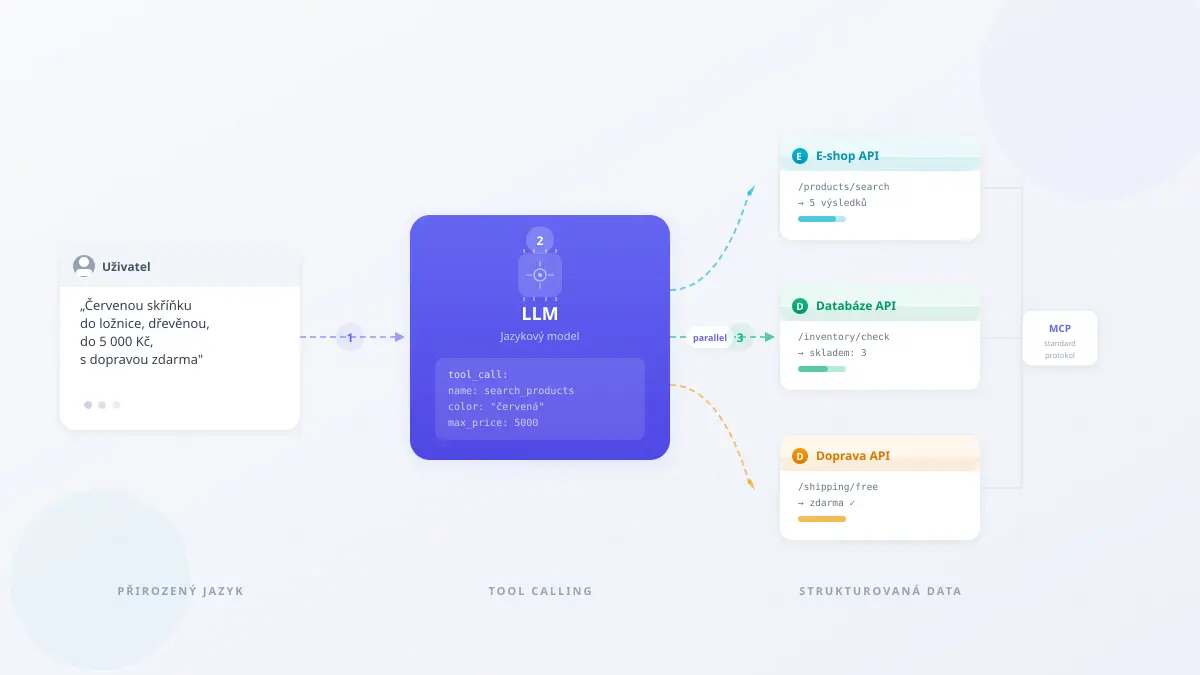
Představte si, že zákazník napíše do vyhledávače: „Chci červenou skříňku do ložnice, dřevěnou, do 5 000 Kč, s dopravou zdarma.“ Klasický vyhledávač si s tím poradí přibližně — vrátí stovky výsledků, z nichž většina nesplní všechna kritéria najednou. Ale co kdyby jazykový model dokázal tuto větu rozebrat, zavolat API e-shopu s přesnými filtry (kategorie: skříňky, materiál: dřevo, barva: červená, cena_max: 5000, doprava: zdarma) a rovnou vrátit pět relevantních produktů?
Přesně o tom je tool calling — schopnost velkých jazykových modelů (LLM) nejen generovat text, ale také zavolat externí nástroje, databáze a služby. A přesně tady se rozhoduje, zda AI přestane být sofistikovaný chatbot a stane se skutečným asistentem, který za vás věci skutečně dělá.
Tento článek mapuje, které z volně dostupných (open-source) modelů tuto schopnost skutečně zvládají — a které ji jen předstírají. Zaměřuje se na modely relevantní pro produkční nasazení: rodinu Llama 3.1, Llama 3.3 70B, Google Gemma a kontroverzní Llama 4. Vychází z benchmarkových dat BFCL (Berkeley Function-Calling Leaderboard), dokumentace inference frameworků vLLM a llama.cpp, GitHub issues a komunitních zkušeností k únoru 2026.
Shrnutí pro spěchající: Pro produkční tool calling je dnes nejlepší volbou Llama 3.3 70B — ověřená kvalita, nulová chybovost parsování, drop-in náhrada za starší Llama 3.1 70B. Gemma se pro tool calling nehodí. Llama 4 je neověřená a reputačně poškozená. Pokud potřebujete paralelní tool calling ve vLLM, sáhněte po Qwen 2.5 72B (nebo novějším Qwen 3) či xLAM-2 70B.
Co je tool calling a proč na něm záleží
Od chatbotu k agentovi
Jazykový model bez tool callingu je jako encyklopedista zavřený v knihovně — ví hodně, ale nemůže se podívat z okna, aby zjistil, jestli venku prší. Dokáže odpovědět na otázku „Jaké bude zítra počasí?“, ale pouze obecně. Nedokáže se připojit k meteorologické službě a vrátit aktuální předpověď.
Tool calling (někdy nazývaný „function calling”) je schopnost modelu rozpoznat, že na zodpovězení otázky potřebuje externí informaci nebo akci, a vygenerovat strukturovaný požadavek — typicky ve formátu JSON — který systém automaticky zpracuje. Model nevykonává kód přímo. Místo toho řekne: „Potřebuji zavolat funkci get_weather s parametrem city='Praha'“, a obsluhující systém (orchestrátor) toto volání provede a výsledek modelu vrátí.
V praxi to znamená, že model může prohledávat databáze, volat API, spouštět výpočty, odesílat e-maily nebo řídit celé workflow — ovšem pouze pokud mu tuto schopnost dáme a pokud ji zvládne spolehlivě.
Proč je to klíčové pro vyhledávání a e-commerce
Pro firmy jako Seznam.cz, Alza nebo Heureka představuje tool calling zásadní technologický skok. Namísto toho, aby uživatel zadal klíčová slova a procházel výsledky, může popsat svůj záměr přirozeným jazykem — a model na základě tohoto záměru zavolá správné API s přesnými parametry.
Typický scénář: uživatel zadá „levný hotel v Krkonoších na víkend pro rodinu s dětmi, s bazénem“. Model z toho extrahuje strukturované parametry (lokace: Krkonoše, termín: nejbližší víkend, typ: rodinný, vybavení: bazén, řazení: cena vzestupně) a zavolá API ubytovacího portálu. Výsledkem je přesný seznam místo stovek nepřesných odkazů.
V praxi je nejčastějším use case tool callingu vzor RAG (Retrieval-Augmented Generation) — model zavolá vyhledávací nebo databázový nástroj, získá relevantní data a na jejich základě sestaví odpověď. Místo toho, aby se spoléhal výhradně na znalosti z tréninku, pracuje s aktuálními daty z vašich systémů. Pro e-commerce a vertikální vyhledávání je RAG přes tool calling de facto standardní architektura — model jako inteligentní „dispatcher“, který ví, které API zavolat a s jakými parametry.
Co je paralelní tool calling a proč je důležitý
Paralelní tool calling nastává, když model v jednom kroku vygeneruje více volání najednou — tedy řekne: „Zavolej současně API počasí, API restaurací a API dopravy.“ Orchestrátor pak všechna volání spustí paralelně místo sekvenčně.
Rozdíl v rychlosti je dramatický. Pokud každé API volání trvá 200 milisekund a potřebujete výsledky ze tří služeb, sekvenční přístup zabere 600 ms. Paralelní přístup zabere stále jen ~200 ms — protože všechna volání běží současně. U komplexních dotazů, které vyžadují data z pěti až deseti zdrojů, může paralelní přístup zkrátit odezvu z několika sekund na zlomek sekundy.
Ne každý dotaz vyžaduje paralelní volání. Jednoduché otázky jako „Kolik je hodin v Tokiu?“ potřebují jediné volání. Ale u složitých dotazů — „Porovnej ceny letenek do Barcelony, doporuč hotel blízko pláže a najdi restaurace s vegetariánským menu“ — je paralelní přístup nezbytný pro přijatelnou rychlost odezvy.
Jak tool calling technicky funguje
Anatomie jednoho volání
Celý proces má čtyři kroky:
1. Definice nástrojů. Před zahájením konverzace systém modelu řekne, jaké nástroje má k dispozici. Každý nástroj má jméno, popis a definici parametrů — podobně jako dokumentace API. Například:
Nástroj: search_products
Popis: Vyhledá produkty v e-shopu Parametry: - category (text): kategorie produktu - max_price (číslo): maximální cena v Kč - color (text, volitelný): barva
2. Rozhodnutí modelu. Model obdrží uživatelovu otázku a seznam nástrojů. Na základě toho se rozhodne: buď odpoví přímo (pokud nepotřebuje žádný nástroj), nebo vygeneruje jedno či více volání nástrojů s konkrétními parametry.
3. Provedení volání.Orchestrátor (softwarová vrstva mezi modelem a API) převezme vygenerované volání, provede ho proti skutečnému API a získá výsledek.
4. Zpracování výsledku. Model obdrží výsledky volání a na jejich základě formuluje odpověď uživateli — nebo se rozhodne zavolat další nástroj (multi-step workflow).
Formáty: jak model volání zapisuje
Různé modely používají různé formáty pro zápis volání. Existují tři hlavní přístupy:
OpenAI formát (de facto průmyslový standard) používá pole JSON objektů. Každé volání má unikátní identifikátor, jméno funkce a argumenty v JSON:
{ "tool_calls": [ {"id": „call_1“, "function": {"name": „get_weather“, "arguments": "{\"city\": \"Praha\"}"}}, {"id": „call_2“, "function": {"name": „get_weather“, "arguments": "{\"city\": \"Brno\"}"}} ] }
Hermes formát (rozšířený v open-source světě) používá XML tagy, kde každé <tool_call>obsahuje JSON s názvem funkce a argumenty. Používají ho modely Qwen, Functionary a řada dalších.
Pythonic formát (rostoucí popularita) zapisuje volání jako Python kód — [get_weather(city='Praha'), get_weather(city='Brno')]. Tento formát přirozeně reprezentuje paralelní volání jako seznam a používá ho Llama 4.
Formát sám o sobě neovlivňuje kvalitu — důležité je, zda model generuje správné názvy funkcí, správné parametry a správně se rozhoduje, kdy volat a kdy ne.
Nad těmito formáty vzniká standardizační vrstva: MCP (Model Context Protocol), otevřený standard od Anthropicu (listopad 2024), který definuje jednotný způsob, jak LLM komunikuje s externími nástroji — od definice nástrojů přes volání až po zpracování výsledků. MCP se rychle šíří ekosystémem (podporuje ho LangChain, řada IDE a postupně i inference frameworky) a směřuje k roli univerzálního „USB konektoru“ mezi modely a nástroji. Pro vývojáře to znamená: pokud dnes nástroje vystavíte přes MCP server, budou fungovat s libovolným modelem, který MCP podporuje — bez nutnosti přepisovat integraci pro každý model zvlášť.
Modely pod drobnohledem
Jak měříme kvalitu tool callingu
Než se ponoříme do konkrétních modelů, je nutné vysvětlit, jak se kvalita tool callingu měří — protože právě tady bývá nejvíc zmatků.
BFCL (Berkeley Function-Calling Leaderboard) je nejuznávanější benchmark pro hodnocení tool callingu. Testuje modely ve čtyřech kategoriích: jednoduché volání (single function), paralelní volání více různých funkcí (parallel multiple), paralelní volání stejné funkce s různými parametry (parallel) a volání s chybějícími informacemi, kdy model musí rozpoznat, že nemá dost dat (missing parameters). BFCL prošel od roku 2024 čtyřmi verzemi: V1 a V2 testují single-turn scénáře, V3 (září 2024) přidal multi-turn konverzace a V4 (červenec 2025) přidal komplexní agentic evaluace včetně web search a paměti.
Pozor na verze: Skóre z různých verzí BFCL nejsou vzájemně srovnatelná. V3 a V4 jsou výrazně náročnější než V1/V2 — model, který dosahuje 85 % na V1, může na V4 spadnout pod 60 %. V tomto článku uvádíme u každého skóre verzi BFCL, ze které pochází.
Pro orientaci: na BFCL V4 (nejaktuálnější verze) dosahuje Claude Opus 4.1 přibližně 70 %, Claude Sonnet 4 rovněž kolem 70 % a GPT-5 přibližně 59 %. Nejlepší open-source modely se na V2 pohybují v rozmezí 75–88 %, ale na V4 výrazně níže. Cokoli pod 60 % na V2 je pro produkci problematické.
Klíčové upozornění: BFCL měří formální správnost výstupu — tedy zda model vygeneroval syntakticky správný JSON se správnými parametry. Neměří, zda model správně rozhodl, že má volat (a ne odpovědět přímo), ani zda parametry odpovídají skutečnému záměru uživatele. Reálný výkon v produkci bývá nižší.
Llama 3.1: model, který zavedl tool calling do open-source
Přesné velikosti:
- Llama 3.1 8B — přibližně 8 miliard parametrů
- Llama 3.1 70B — přibližně 70 miliard parametrů
- Llama 3.1 405B — přibližně 405 miliard parametrů
Všechny tři varianty sdílejí stejnou architekturu (dense Transformer), liší se počtem vrstev a šířkou „paměti“ (hidden size). Kontext je 128 000 tokenů u všech verzí — zhruba 96 000 slov, tedy celá kniha.
Co přinesl Llama 3.1: Před Llamou 3.1 (červenec 2024) open-source modely tool calling buď nepodporovaly vůbec, nebo jen experimentálně. Llama 3.1 byla první široce dostupná řada s nativní podporou — Meta přidala speciální tokeny (značky v „abecedě“ modelu) pro rozpoznání a formátování volání nástrojů. Model se naučil, kdy volat, jaké parametry použít a jak zpracovat odpověď.
Praktický výkon podle velikosti:
Nezávislé testování firmy Braintrust odhalilo překvapivé rozdíly mezi velikostmi:
8B model selhal ve 20 % testovacích případů při parsování odpovědí — jinými slovy, každé páté volání bylo syntakticky nesprávné (chybějící závorky, špatné JSON formátování, neúplné parametry). Meta sama varuje: „8B model nedokáže spolehlivě udržet konverzaci současně s definicemi nástrojů.“ Doporučuje ho pouze pro izolované, jednoúčelové volání — zavolat jednu funkci na jeden dotaz, bez historie konverzace.
70B model dosáhl nulové chybovosti parsování v testech Braintrust — lepší výsledek než 405B i než komerční GPT-4o. Na BFCL V1 dosahuje skóre přibližně 84,8 %, na V2 pak 77,5 %. Databricks na základě vlastního testování potvrdil, že Llama 3.1 70B je překvapivě silná a funguje konkurenceschopně oproti komerčním modelům.
405B model měl paradoxně vyššíchybovost parsování než 70B — několik selhání v testech, kde 70B uspěla bezchybně. Na BFCL V1 dosáhl 88,5 % (nejvyšší ze tří), ale v praxi se ukázalo, že 70B nabízí lepší poměr kvality a ceny.
Klíčový závěr: Pro produkční tool calling je Llama 3.1 70B výrazně lepší volba než 8B (příliš nespolehlivá) i 405B (dražší inference, marginálně lepší).
Paralelní tool calling: Llama 3.1 formálně podporuje paralelní volání, ale s omezeními. Inference framework vLLM nemá pro řadu Llama 3.x dedikovaný parser pro paralelní výstupy. V llama.cpp je paralelní volání dostupné, ale ve výchozím stavu vypnuté — je třeba ho explicitně zapnout příznakem parallel_tool_calls: true. Praktická spolehlivost paralelního volání u Llama 3.1 je nižší než u sekvenčního (jednotlivého) volání.
Llama 3.3 70B: vylepšený nástupce a dnešní nejlepší volba
Llama 3.3 existuje výhradně jako 70B model — vydaný v prosinci 2024, žádná 8B verze nikdy nevznikla. Architektura je identická s Llama 3.1 70B (stejný počet vrstev, stejná šířka), ale prošla výrazně lepším „post-trainingem“ — Meta použila pokročilejší techniky supervised fine-tuningu (SFT, učení na příkladech správných odpovědí) a RLHF (reinforcement learning from human feedback, učení na základě lidské zpětné vazby).
Meta explicitně uvádí: „Tento model nahrazuje Llama 3.1 70B. Vývojáři by měli používat nový model všude, kde by jinak použili Llama 3.1 70B.“
Proč je lepší pro tool calling:
Na BFCL V2 dosahuje Llama 3.3 70B skóre 77,3 % oproti 77,5 % u Llama 3.1 70B — rozdíl 0,2 bodu je statisticky zanedbatelný. Proč tedy tvrdíme, že je lepší?
Protože BFCL V2 měří pouze formální správnost volání v single-turn scénářích. Reálná kvalita tool callingu závisí na dalších faktorech — a tady Llama 3.3 dramaticky vyniká:
- IFEval (jak přesně model dodržuje instrukce): Llama 3.3 dosahuje 92,1 oproti 87,5 u Llama 3.1
- MATH (přesnost numerických výpočtů): Llama 3.3 dosahuje 77,0 oproti 67,8 u Llama 3.1
- HumanEval (kvalita generovaného kódu): Llama 3.3 dosahuje 88,4 oproti 80,5 u Llama 3.1
- MMLU PRO (obecné znalosti a uvažování): Llama 3.3 dosahuje 68,9 oproti 66,4 u Llama 3.1
Zlepšení v IFEval (instruction following, +4,6 bodu) přímo ovlivňuje tool calling: model lépe dodržuje požadovaný formát výstupu, přesněji vyplňuje parametry a spolehlivěji se rozhoduje, kdy volat nástroj a kdy odpovědět přímo. Zlepšení v MATH (+9,2 bodu) znamená přesnější extrakci a zpracování numerických parametrů — cen, dat, množství. Zlepšení v HumanEval (+7,9 bodu) se projeví v kvalitě generovaného JSON.
Firma Groq (provozovatel inference infrastruktury) potvrzuje, že Llama 3.3 70B je kvalitou překvapivě blízko většímu Llama 3.1 405B — model pětinové velikosti s podobnou kvalitou.
Podpora ve frameworcích: Llama 3.3 70B používá stejný formát tool callingu jako Llama 3.1 — parser llama3_json ve vLLM, llama3v SGLang, nativní podpora v llama.cpp. Přechod z Llama 3.1 70B na 3.3 70B nevyžaduje žádné změny v kódu ani konfiguraci — je to „drop-in replacement“ (náhrada bez úprav).
Paralelní tool calling má stejná omezení jako u Llama 3.1 — ve vLLM nepodporováno pro řadu 3.x, v llama.cpp přes explicitní flag.
Llama 4: technicky zajímavá, reputačně zničená
Llama 4 je příběh o tom, co se stane, když marketingový tlak předběhne inženýrskou realitu.
Architektura — MoE místo dense:
Llama 4 přinesla zásadní architektonickou změnu. Zatímco Llama 3.x jsou „dense“ modely (všechny parametry se aktivují při každém tokenu), Llama 4 používá Mixture of Experts (MoE)— model obsahuje mnoho „expertních“ modulů, ale při zpracování každého tokenu aktivuje jen zlomek z nich:
- Scout: 109 miliard parametrů celkem, ale pouze 17 miliard aktivních (16 expertů, aktivuje 1). Deklarovaný kontext 10 milionů tokenů.
- Maverick: 400 miliard parametrů celkem, ale pouze 17 miliard aktivních (128 expertů, aktivuje 1). Kontext 1 milion tokenů.
Výhoda MoE: inference (generování odpovědí) je rychlá a levná, protože se počítá jen s aktivními parametry. Nevýhoda: trénink je složitější a model se může chovat nepředvídatelně — různí experti se mohou „specializovat“ na různé úlohy nerovnoměrně.
Co se skutečně stalo — benchmark skandál:
Meta vydala Llama 4 Scout a Maverick 5. dubna 2025 — neobvykle v sobotu. Na LMArena (dříve Chatbot Arena, nejprestižnější komunitní žebříček modelů) nahrála speciální „experimentální“ verzi Mavericka, která byla optimalizována pro lidské hodnotitele — byla ukecanější, používala emoji a byla navržena tak, aby v slepém hlasování „okouzlila“ uživatele. Tato verze skončila na 2. místě žebříčku.
Když LMArena přidala standardní veřejnou verzi Mavericka (tu, kterou si mohl kdokoli stáhnout z HuggingFace), skončila na 32. místě — za GPT-4o, Claude 3.5 Sonnet i Gemini 1.5 Pro.
Anonymní příspěvek na čínském fóru od údajného ex-zaměstnance Meta tvrdil, že vedení přimíchalo testovací data z benchmarků do tréninku modelu. Ahmad Al-Dahle, viceprezident Meta GenAI, to popřel.
Definitivní potvrzení přišlo od samotného Yanna LeCuna — hlavního AI vědce Meta, průkopníka konvolučních neuronových sítí a držitele Turingovy ceny. LeCun v listopadu 2025 oznámil odchod z Meta a založení vlastního startupu Advanced Machine Intelligence Labs (AMI Labs) zaměřeného na „world models“. V rozhovoru pro Financial Times, publikovaném začátkem ledna 2026, pak řekl, že benchmarkové výsledky Llamy 4 „byly trochu zfalšované“ — tým použil různé modely pro různé benchmarky, aby dosáhl lepších výsledků. LeCun doplnil, že Mark Zuckerberg ztratil důvěru v zodpovědný tým a následně provedl zásadní reorganizaci AI divize — včetně přijetí Alexandr Wanga, tehdy šéfa Scale AI, jako nového Chief AI Officera Meta v rámci investice přibližně 14 miliard dolarů do Scale AI.
Reálný výkon:
Komunitní testy ukázaly propastný rozdíl mezi deklarovaným a skutečným výkonem. Na Aider polyglot coding benchmarku dosáhl Maverick pouhých 16 %. Rootly AI Labs naměřila Mavericku nejnižší přesnost ze všech testovaných modelů (69,5 %) na GMCQ benchmarku založeném na reálných GitHub issues — horší výsledek než starší modely včetně Llama 3.3 70B. Deklarovaný kontext 10 milionů tokenů u Scoutu se ukázal jako „virtuální“ — komunitní testy ukazují výraznou degradaci kvality výrazně pod touto hranicí. Jeden z nezávislých testů zaznamenal u Scoutu pouhých 15,6 % přesnosti při 128K tokenech, zatímco Gemini 2.5 Pro na stejné délce dosahuje přes 90 %.
Tool calling u Llama 4:
Meta přešla u Llama 4 na pythonic formát volání (místo JSON u Llama 3.x). Ve vLLM existuje parser llama4_pythonic, v SGLang parser llama4. Paralelní tool calling je nativně podporován. Nicméně na BFCL leaderboardu neexistují žádné skóre pro Llama 4 Scout ani Maverick — modely nebyly testovány nebo výsledky nebyly zveřejněny. Praktická kvalita tool callingu tak zůstává neověřená.
Doporučení: Llama 4 není nepoužitelná, ale pro tool calling představuje neprokázanou volbu. Pokud ji zvažujete, důkladně testujte na vlastních use cases a porovnejte s Llama 3.3 70B, která má ověřený track record.
Gemma 3 27B: silný model, slabý tool calling
Google Gemma je řada otevřených modelů odvozených z komerční Gemini. Gemma 3 27B, vydaná v březnu 2025, přidala multimodalitu (zpracování obrázků) a rozšířila kontext na 128 000 tokenů.
Proč Gemma selhává v tool callingu:
Jádro problému je jednoduché: Gemma modely nemají žádné dedikované tokeny pro tool calling. Co to znamená?
Modely jako Llama 3.1 byly natrénovány s rozšířenou „abecedou“ — kromě běžných slov a znaků obsahují speciální značky (tokeny) jako <|python_tag|>nebo <|eom_id|>, které modelu signalizují: „Teď generuji volání nástroje“ a „Skončil jsem s voláním.“ Díky těmto značkám model jednoznačně odliší běžný text od strukturovaného volání — a inference framework přesně ví, kde volání začíná a končí.
Gemma nic takového nemá. Google oficiálně uvádí: „Gemma nevypisuje žádný speciální token pro volání nástroje. Váš framework musí detekovat volání kontrolou struktury výstupu.“ V praxi to znamená, že tool calling funguje pouze přes prompt engineering — do promptu vložíte definice funkcí a požadovaný formát výstupu, doufáte, že model vygeneruje správný JSON, a pak se pokoušíte výstup naparsovat.
Důsledky jsou zásadní:
Absence nativního parseru ve frameworcích. Ve vLLM neexistuje oficiální parser pro Gemma — feature requesty na GitHubu zůstaly bez oficiální implementace. V SGLang rovněž žádný Gemma parser není.
Nespolehlivé paralelní volání.Bez nativních tokenů a tréninku na tool calling formátu model nedokáže spolehlivě vygenerovat více volání najednou.
Nízké BFCL skóre. Gemma 3 27B dosahuje na BFCL výrazně nižších skóre než modely s nativní podporou — přibližně o 18 bodů méně než Llama 3.3 70B.
FunctionGemma — specializovaná varianta. Google v prosinci 2025 vydal FunctionGemma — model o 270 milionech parametrů odvozený z Gemma 3, s vlastními tokeny pro tool calling. Na evaluaci „Mobile Actions“ dosahuje 58 % přesnosti v base verzi a až 85 % po doménově specifickém fine-tuningu, ale jeho velikost ho omezuje na edge scénáře (mobilní zařízení, IoT). Pro serverové nasazení je příliš malý.
Závěr: Gemma modely se pro tool calling v produkci nedoporučují. Jsou to vynikající modely pro jiné úlohy (generování textu, analýza obrázků u Gemma 3), ale bez nativní podpory tool callingu a framework integrace představují zbytečné riziko.
Inference frameworky: software, který modely provozuje
Model sám o sobě je jen soubor čísel (vah neuronové sítě). Aby mohl odpovídat na dotazy a volat nástroje, potřebuje inference framework — software, který model načte do paměti GPU, zpracovává dotazy a formátuje výstupy. Výběr frameworku zásadně ovlivňuje, zda tool calling funguje správně.
vLLM — produkční standard
vLLM (Virtual Large Language Model) je nejrozšířenější framework pro produkční nasazení. Nabízí vysoký výkon díky technikám jako PagedAttention (efektivní správa GPU paměti) a continuous batching (současné zpracování více dotazů). Pro tool calling poskytuje dedikované parsery pro různé rodiny modelů:
- Llama 3.1 / 3.3 → parser llama3_json, paralelní TC nepodporováno
- Llama 4 → parser llama4_pythonic, paralelní TC podporováno
- Qwen 2.5 / 3 → parser hermes, paralelní TC podporováno
- xLAM-2 → parser xlam, paralelní TC podporováno
- FunctionGemma → podporováno, paralelní TC ne
- Gemma 3 (27B) → parser neexistuje (pouze komunitní workaround), paralelní TC ne
Spuštění s tool calling vyžaduje specifické příznaky:
vllm serve meta-llama/Llama-3.3-70B-Instruct -–enable-auto-tool-choice –-tool-call-parser llama3_json -–chat-template tool_chat_template_llama3.1_json.jinja
Zásadní detail: vLLM nepodporuje paralelní tool calling pro řadu Llama 3.x — i když model je schopen vygenerovat více volání, parser je nedokáže zpracovat. Pro Llama 4 a Qwen paralelní volání funguje.
llama.cpp — efektivní alternativa pro CPU a menší GPU
llama.cpp je framework optimalizovaný pro provoz na běžném hardwaru — podporuje CPU inference, menší GPU a kvantizované modely (zmenšené modely s nižší přesností, ale dramaticky menšími nároky na paměť). Pro tool calling je třeba spustit server se specifickými příznaky:
llama-server –model model.gguf –jinja -fa
Paralelní tool calling je ve výchozím stavu vypnutý. Zapíná se přidáním "parallel_tool_calls": true do požadavku. Kvalita závisí na modelu — llama.cpp podporuje Llama 3.1/3.3, Qwen, Mistral i Llama 4.
Známý problém: mezi verzemi llama.cpp dochází k regresím — jeden uživatel reportoval pokles úspěšnosti tool callingu z 10/10 na 2/10 po aktualizaci. Při produkčním nasazení je vhodné fixovat konkrétní verzi.
SGLang — rychlý, ale méně ověřený
SGLang nabízí vysoký výkon a podporu tool callingu pro Qwen, Llama 3.x, Llama 4, Mistral a DeepSeek. Parsery jsou llama3pro Llama řadu a llama4 pro Llama 4. Známé problémy zahrnují občasné chyby v indexování nástrojů a nestabilitu při vysokém zatížení.
Co se stane bez správného parseru
Pokud inference framework nemá dedikovaný parser pro daný model, tool calling buď nefunguje vůbec (framework nerozpozná, že model chce volat nástroj), nebo funguje nespolehlivě (generický parser špatně identifikuje hranice volání, parametry nebo názvy funkcí). Proto je kombinace model + framework + parser klíčová — nestačí, aby model tool calling „uměl“, musí ho umět i framework zpracovat.
Právě tuto fragmentaci řeší MCP — pokud váš inference stack podporuje MCP, definujete nástroje jednou a přepínáte modely bez změn na straně nástrojů. V praxi to zatím funguje hlavně u komerčních API (Claude, GPT); u self-hosted open-source modelů je MCP podpora teprve v počátcích.
Realita vs. benchmarky: co říkají čísla
BFCL skóre v kontextu
- Llama 3.3 70B — BFCL V2: 77,3 %, praktická spolehlivost vysoká (0 % selhání parsování)
- Llama 3.1 70B — BFCL V2: 77,5 %, praktická spolehlivost vysoká (0 % selhání parsování)
- Llama 3.1 70B — BFCL V1: 84,8 %, praktická spolehlivost vysoká
- Llama 3.1 405B — BFCL V1: 88,5 %, praktická spolehlivost střední (občasná selhání parsování)
- Llama 3.1 8B — BFCL V1: ~76 %, praktická spolehlivost nízká (20 % selhání parsování)
- Gemma 3 27B — BFCL V2 (prompt): ~59 %, praktická spolehlivost nízká (bez nativní podpory)
- Llama 4 Maverick — netestováno, praktická spolehlivost neověřená
Co tyto čísla znamenají v praxi?
BFCL skóre 77,3 % (V2) neznamená, že každé čtvrté volání selže. Benchmark testuje široké spektrum scénářů od triviálních po extrémně složité. V produkci, kde definice nástrojů jsou konzistentní a dotazy předvídatelné, bývá úspěšnost vyšší. Na druhou stranu, benchmarky neměří edge cases specifické pro vaši doménu — proto je vlastní testování nezbytné.
Důležité je rozlišovat verze benchmarku: na BFCL V4, který zahrnuje multi-turn a agentic scénáře, jsou skóre výrazně nižší pro všechny modely — i komerční. Claude Opus 4.1 dosahuje na V4 přibližně 70 %, GPT-5 kolem 59 %. Open-source modely budou na V4 zákonitě ještě níže.
Reálné agentic benchmarky jsou střízlivější
Sofistikovanější benchmarky jako τ-bench (tau-bench), které testují celé agentic workflow (model musí provést sérii kroků k dosažení cíle v simulovaném prostředí zákaznické podpory), ukazují výrazně nižší čísla. GPT-4o dosahuje pod 50 % úspěšnosti na τ-bench (konkrétně ~61 % na retail doméně a ~35 % na airline doméně). Metrika pass^8 (úspěšnost přes 8 po sobě jdoucích pokusů o stejný úkol) klesá pod 25 % v retail doméně — to znamená, že jen ve čtvrtině případů model úspěšně a konzistentnědokončí celý workflow.
Pro tool calling to implikuje: jednoduché, izolované volání (zavolej jednu funkci s jasnými parametry) funguje spolehlivě. Složité, vícekrokové workflow (zavolej funkci A, na základě výsledku zavolej B nebo C, zkombinuj výsledky a zavolej D) jsou stále nespolehlivé u všech modelů.
Srovnávací přehled pro rozhodování
Kdy použít který model
- Produkční tool calling, nové projekty → Llama 3.3 70B — nejlepší poměr kvalita/cena, drop-in replacement za 3.1
- Existující deployment na Llama 3.1 70B → migrace na Llama 3.3 70B — žádné změny v kódu, lepší výkon
- Omezený hardware (16 GB GPU) → Llama 3.1 8B (kvantizovaná) — jen pro jednoduché, izolované volání
- Potřeba paralelního TC ve vLLM → Qwen 2.5 72B nebo xLAM-2 70B — vLLM nepodporuje paralelní TC pro Llama 3.x
- Multimodální + tool calling → Llama 4 Scout (opatrně) — jediný open-source MoE s nativním TC, ale neověřený
- Analýza obrázků bez tool calling → Gemma 3 27B — výborná pro vision, nevhodná pro TC
Co nedoporučujeme
Gemma pro tool calling — strukturální handicap (absence FC tokenů, chybějící framework podpora) nelze kompenzovat prompt engineeringem na produkční úrovni spolehlivosti.
Llama 3.1 8B pro cokoli složitějšího— 20% selhávání parsování a Metou potvrzená neschopnost kombinovat konverzaci s tool calling instrukcemi.
Llama 4 bez vlastního testování — chybějící BFCL data a benchmark skandál vytvářejí příliš velkou nejistotu.
Praktická doporučení pro implementaci
1. Začněte s Llama 3.3 70B + vLLM
Pro většinu produkčních scénářů je toto nejbezpečnější startovní kombinace. Pokud nepotřebujete paralelní tool calling (většina jednoduchých use cases ho nevyžaduje), dostanete ověřenou kvalitu s minimálním rizikem.
2. Pro paralelní tool calling použijte Qwen nebo xLAM-2
Pokud váš use case vyžaduje paralelní volání více nástrojů najednou (např. multi-vertikální vyhledávání) a používáte vLLM, zvažte Qwen 2.5 72B (parser hermes) nebo Salesforce xLAM-2 70B (parser xlam). Oba modely mají ověřenou podporu paralelního TC ve vLLM.
3. Testujte na vlastních datech
Žádný benchmark nenahradí testování na vašich konkrétních nástrojích, parametrech a uživatelských dotazech. Vytvořte testovací sadu alespoň 100 příkladů pokrývajících běžné i edge-case scénáře a měřte úspěšnost na ní. Pokud stavíte RAG pipeline, testujte celý řetězec end-to-end — od uživatelského dotazu přes extrakci parametrů, volání retrieval API, až po kvalitu finální odpovědi. Chyba v kterémkoli kroku degraduje celkový výsledek.
4. Implementujte fallback mechanismus
I ten nejlepší model občas selže. Navrhněte systém s fallback logikou — pokud model vygeneruje neplatné volání, vraťte se k jednoduchému keyword vyhledávání nebo požádejte uživatele o upřesnění.
5. Fixujte verze všech komponent
Model, inference framework i chat template — fixujte konkrétní verze v produkci. Aktualizace kdykoli z nich může způsobit regresi v tool calling kvalitě (dokumentovaný problém u llama.cpp).
Výhled: co přijde dál
Trh s open-source modely pro tool calling se rychle vyvíjí. Salesforce xLAM-2 70B (specializovaný model pro function calling) dosáhl na BFCL skóre srovnatelného s komerčními modely. Qwen 3 od Alibaby posiluje paralelní tool calling. DeepSeek V3 přináší MoE architekturu s dobrou tool calling podporou.
Meta vyvíjí nástupce současných modelů: textový LLM s kódovým názvem Avocado (nástupce řady Llama, zaměřený na coding a tool orchestraci) a multimodální model Mango (generování obrázků a videa). Oba jsou plánovány na první polovinu 2026 a vznikají v rámci nové divize Meta Superintelligence Labs pod vedením Alexandr Wanga. Pokud se potvrdí spekulace o opuštění open-weight přístupu — Avocado by mohl být první proprietární model z Meta —, open-source ekosystém přijde o jednoho z hlavních přispěvatelů. To může urychlit fragmentaci: místo jedné dominantní řady (Llama) bude trh rozdělen mezi Qwen, xLAM, Mistral a další.
Pro organizace plánující nasazení tool callingu to znamená: investujte do abstrakčních vrstev (LiteLLM, LangChain) a standardů jako MCP, které umožní snadný přechod mezi modely, a neplánujte dlouhodobou závislost na jedné modelové řadě. MCP se navíc stává přirozeným rozhraním pro RAG architektury — nástroje pro vyhledávání, databázové dotazy i volání externích API lze vystavit jako MCP servery a dynamicky je nabízet libovolnému modelu.
Metodologická poznámka
Tento článek vychází z BFCL leaderboardu (V1–V4), oficiální dokumentace vLLM a SGLang, GitHub issues a diskusí, HuggingFace model cards, nezávislých evaluací (Braintrust, Databricks, Rootly AI Labs, Groq) a mediálních zpráv (Financial Times, TechCrunch, The Register, VentureBeat). Data jsou aktuální k únoru 2026. Benchmarkové skóre se mohou měnit s novými verzemi modelů a evaluačních sad. Praktická spolehlivost závisí na konkrétním use case, konfiguraci a verzi frameworku.
BFCL skóre uváděná v článku pocházejí z různých verzí benchmarku — u každého čísla je uvedena příslušná verze. Skóre z různých verzí nejsou přímo srovnatelná, protože novější verze přidaly náročnější testovací kategorie (multi-turn, agentic).
Transparentnost tvorby:
Koncepce, struktura a redakční linie článku jsou dílem autora, který vypracoval obsahovou skicu, stanovil klíčové teze a řídil celý proces tvorby. Generativní AI (Claude, Anthropic) byla využita jako technický nástroj pro rešerši, ověřování faktů a rozepsání autorovy předlohy.
Autor výstupy průběžně redigoval, ověřil klíčová zjištění a schválil finální znění. Žádná část textu nebyla publikována bez lidské kontroly. Všechny faktické údaje byly ověřeny proti veřejně dostupným zdrojům uvedeným v textu.
Postup je v souladu s požadavky Čl. 50 Nařízení EU 2024/1689 (AI Act) na transparentnost AI-generovaného obsahu. #poweredByAI






