

Článek
Generativní neuronky přinášejí revoluci všude a do vyhledávání možná nejvíc. Spousta lidí už klasický vyhledávač typu Google neotevírá a jde rovnou do nějakého konverzačního AI rozhraní. Brzo se tomu přizpůsobí i prohlížeče a řádek adresy. Ten řádek, který Google před 20 lety v Chromu změnil z řádku adresy na řádek dotazu, se brzo stane hlavně řádkem začátku konverzace.
Už každý ví, jak jsou AI úžasné, když o tématu nic nevím (úžasné!), a jak jsou nepřesné, když mi odpovídají v oblasti, které fakt rozumím (nic moc). Že občas halucinují. Všichni z halucinování tak trochu máme radost v (marné) naději, že nás myslící stroje nenahradí (nahradí). Ale o tom jsem psát nechtěl. Chtěl jsem upozornit na to, že kromě halucinací existují další typy chyb, které generativní neuronky můžou dělat, pokud jde o vyhledávání. Jde o špatnou formulaci dotazu, špatné vyhledávání, konfirmační pořadí kroků, záměrné zkreslení a zdání větší přesvědčivosti.
Napřed si něco řekneme o čísle 70 miliard. Je to řádový počet parametrů větší generativní neuronky, například LLaMA 3. 70 miliard vypadá jako obrovské číslo a je fakt, že v mateřské školce jsem ho neznal, ale při bližším zkoumání to zas tak velké číslo není. Lidé často ztrácejí u čísel představu o velikosti někde nad desítkami miliónů. Milión jako bilión, máma bába, flaška taška. Ono je totiž těžké si ta čísla představit. Dobré je vnímat dekadický logaritmus, což je vlastně počet nul za jedničkou. Například 70 miliard má sedmičku a 10 nul. Fajn, ale co vlastně znamená sedmička a deset nul? Proto si raději představuji velká čísla jako mocniny, respektive si je odmocňuji nebo nějak faktorizuji. V případě (fully connected) neuronek dává docela dobrý smysl vydělit počet parametrů počtem vrstev a zbytek odmocnit. Například pro jednoduchost odhadnu, že neuronka má 70 vrstev. Potom na jednu vrstvu připadá miliarda parametrů. Když je propojen každý neuron s každým neuronem v příští vrstvě (fully connected), tak mi na miliardu parametrů stačí odmocnina z miliardy, což je nějakých 31 tisíc neuronů ve vrstvě. 31 tisíc si už lze představit mnohem snáz. Například je to zhruba velikost aktivní slovní zásoby chytrých lidí. (Což mimochodem není náhoda, ale o tom jindy.)
Tímto přiblble složitým výkladem jsem se snažil říct jedinou věc:
70 miliard je malé číslo.
Je to příliš malé číslo na to, aby se do něj uložilo vědění lidstva. I když má AI třeba 175 miliard parametrů nebo když funguje jako MoE s více „experty“, kdy takových velkých neuronek sedí vedle sebe několik různých, čímž se zvyšují znalosti a schopnosti, pořád se do nich nevejde vědění lidstva, takže spoustu věcí musí hádat. I při použití chytřejších technik jako je třeba řetězení myšlenek (chain of thought) některá data nejde z parametrů neuronky vytáhnout, protože tam prostě nejsou. Podobně tam nemůže být výsledek fotbalu, který se hrál před hodinou. Tak vznikla myšlenka RAG - Retrieval Augmented Generation, tedy generování obohacené vyhledáváním. Funguje následovně:
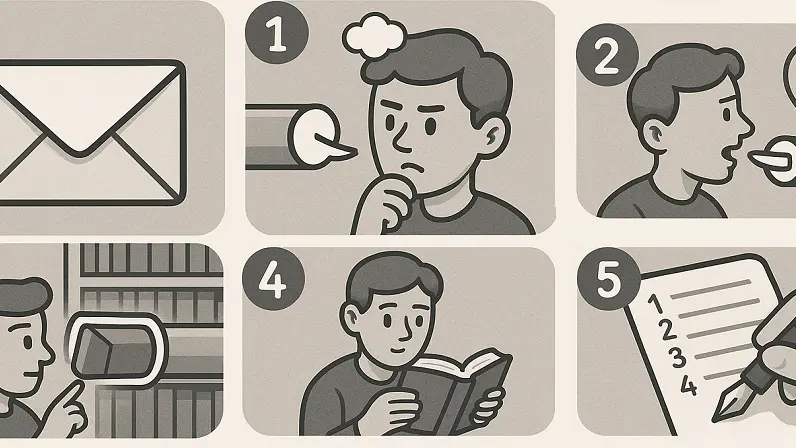
RAG:
0. dostane dotaz
1. zamyslí se, co neví
2. zeptá se na to, co neví
3. dostane odpověď od nějakého vyhledávání
4. výsledky si přečte
5. zamyslí se a sepíše z toho odpověď s odkazy na zdroje
To zní skvěle. RAG pronikl do skoro všech AI nástrojů lidstvo je zachráněno. Jenže ani ne a o tom teď píšu. Co má RAG za problémy:
2. zvorá bod 2 = špatná formulace dotazů
1. zvorá pořadí kroků a zamyslí se moc brzo = konfirmační zkreslení
3. zvorá bod 3 = špatné výsledky vyhledávání
4. záměrné zkreslení
5. a vypadá to celé mnohem přesvědčivěji, protože to obsahuje odkazy na „zdroje“
Teď podrobně:
Když se neuronka zamyslí, co neví, a zeptá se na to, tak to může udělat tisícem různých způsobů. Podle mě je překvapivě těžké udělat to dotazování dobře. Docela hodně se tenhle problém zkoumá, ale je těžké říct, co z teorie prosáklo do prakticky používaných nástrojů. Problematika ve stručnosti:
- když se hledá příliš krátký a obecný dotaz, výsledky jsou nepřesné
- naopak když se hledá příliš dlouhý dotaz, je těžké najít stránky, které by na něj dobře odpovídaly
- velmi dlouhé prompty je obtížné správně rozdělit na pasáže, které si zaslouží vlastní dotaz
- je těžké rozhodnout, na co se zeptat a na co se neptat, když si to generativní neuronka troufne zodpovědět sama
- asi nejzáludnější je, že když se při tvorbě dotazu něco nepovede, tak není pořádně jak změřit, že se to nepovedlo. Uživatelé jsou totiž málo nároční.
Konfirmační retrieval: Zatím jsem popisoval čistě technický problém. Horší epistemický případ nastává, když AI před položením dotazu do vyhledávání provede příliš mnoho úvah a začne si o problematice něco sama neověřeně myslet. Na tuhle neověřenou hypotézu se následně zeptá. Protože jsou internety plné spousty balastu, podaří se jí najít zdroje, které hypotézu potvrzují, ať hledá skoro cokoli. Místo správného režimu, kterému říkám explorační retrieval, se ocitne v konfirmačním retrievalu. Zatím jsem si nevšimnul, že by nějaký běžný AI chat tenhle typ chyby dělal programově, což je fajn. Ale nemusí to být zas tak řídká situace - hlavně díky pokračujícím konverzacím. Po prvním promptu AI něco vyhalucinuje. Uživatel pokračuje v konverzaci. AI sestaví dotaz na základě předchozího kontextu s halucinací. A na problém je zaděláno, protože internety potvrdí skoro všechno. (Obdobou u uživatele je informační bublina.)
Další slabá část je vyhledávání. I dobře položený dotaz se dá zkazit a najdou se blbosti. Protože lepší dotazy pro RAG jsou delší (nesou víc informace), spíš v nich selhává historicky starší způsob textového hledání, kdy se prostě hledají ve stránkách jen slova obsažená v dotazu. Lepší je použít vyhledávání na základě embedingů (vektorových reprezentací dokumentů nebo částí dokumentů). Vektorové hledání má ale zase nevýhodu, že je obtížnější preferovat zdroje z autoritativních zdrojů, protože klasické algoritmy vracejí jen nejbližší zástupce clustru podle shody vektorů a autoritativnost neumějí přímo zohlednit. Běžně se tak třeba může citovat ze špatných automatických překladů úplně převracejících smysl originálu. No prostě je obtížné jen tak bez úprav nasadit na RAG klasický webový vyhledávač, který se běžně soustředí spíš na velmi krátké dotazy uživatelů líných psát.
Záměrné zkreslení je taky príma kapitola. Už dokonce máme zřejmý příklad. V červenci se Grok při odpovídání některých promptů dotazoval, co si o tématu myslí Elon Musk. Naštěstí má Grok natolik transparentní rozhraní, že to v některých konverzacích bylo při podrobnějším rozkliknutí vidět. Představte si ale, že některé nástroje takhle transparentní nebudou. Co všechno se v nich pak může dít?
Tím se dostávám ke svému poslednímu bodu, proč shledám RAG problematickým. Působí prostě odborněji, než skutečně je. Hezký souvislý text protkaný relevantními odkazy jsme byli zvyklí číst jen od někoho, kdo to měl v hlavě srovnané a byl v tématu doslova epistemickou autoritou. Když dnes podobně vypadající text umí vytvořit stroj poskládaný z ne úplně sofistikovaných komponent, mám zvykovou tendenci tomu přikládat důvěryhodnost. To se budu muset odnaučit. I když je pravda, že v mnoha případech RAG zafunguje skvěle a v oblastech, kterým vůbec nerozumím, je vlastně dobrým pomocníkem.




